
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- DB
- GitLab
- judge
- CUDA
- pandas
- TORCH
- LLM
- format
- list
- Linux
- Package
- PostgreSQL
- pytorch
- AI
- file
- Container
- docker
- enV
- git
- KAKAO
- Flask
- Mac
- Paper
- Converting
- Windows
- numpy
- Database
- Laravel
- evaluation
- Python
- Today
- Total
Daily Develope
[Paper] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena 본문
일부내용 요약 및 정리
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Abstract
open-ended 질문에서 모델을 평가하기 위해 강력한 LLM을 평가 도구로 사용해본 연구이다.
LLM 평가와 사람의 선호도 사이의 일치도를 검증하고, 관련된 벤치마크로 (multi-turn의 질문 셋으로 구성된 ) MT-bench와 (온라인을 통해 LLM간 경쟁을 붙이는) Chatbot Arena 플랫폼에 대해 소개한다.
GPT-4와 같은 강력한 LLM을 판단도구로 사용하는 경우 사람과의 일치율이 80% 이상이었으며, 사람들의 선호도 측정 및 설명 가능한 방법 중 하나로 대략적으로 사용 가능할 것으로 보인다.
1. Introduction
대표적으로 사용되는 LLM 벤치마크 중 MMLU와 HELM의 경우, 해당 점수가 실제 사람들의 선호도를 반영하는 것은 아니다. 이는 사용자가 생각하는 유용함과 대화 벤치마크에서 채택하고 있는 평가 기준 사이에 중요한 차이점이 있음을 얘기한다. 이러한 중요한 차이점은 LLM의 주요 능력이라 할 수 있는 객관식 지식(multi-choice knowledge)이나 retrieval 질문 평가에 초점을 두고 있어 발생한 문제이다. (예를들면 멀티턴 대화 중 맥락을 잡아내는 것과 같은 사람들의 선호도에 대한 alignment가 제대로 평가되지 않았다.)
사전 학습된 (fine-tuning되지 않은) LLaMA-13B base 모델과 LLaMA-13B로부터 fine-tune된 모델인 Vicuna-13B를 사용한 대화 벤치마크 성능 시험에서, base 모델이 fine-tune된 모델에 견줄만큼 성능이 나왔음에도 사람들의 선호도가 낮은 결과를 나타냈다. 이를 연구하고자 우리는 MT-bench와 Chatbot Arena를 개발했다. MT-bench는 open-ended question의 한 종류로, chatbot의 멀티턴 대화와 지시대처 능력(instruction-following ability)을 평가하기 위한 벤치마크이다. 그리고 Chatbot Areana는 실세계(wild) 시나리오에서 익명의 챗봇간의 경쟁을 붙이도록 개발된 크라우드소싱 플랫폼이다.
본 논문에서는 사람의 평가 기준과 비교하는 측면에서의 LLM-as-a-judge 연구를 수행했으며; position bias, verbosity bias, self-enhancement bias, 제한된 추론 능력을 포함한 LLM-as-a-judge의 몇 가지 한계점에 대해 설명한다. 한계점 설명 이후에는, 일부 전문가와 크라우드 소싱의 사람들로부터 평가된 3천 개의 각각의 평가 결과가 GPT-4의 판단 결과와 80% 이상의 일치율을 나타낸 것에 대해서 설명할 것이다(해당 수치는 사람이 평가한 결과간의 일치율과 동일하다). 결론적으로, LLM-as-a-judge는 사람의 선호도를 즉각적으로 평가할 수 있는 한 가지 유연한 방법으로, 그 동안 사용되어왔던 사람에 의한 평가를 대신할 수 있을 것이다.
본 논문은 2가지 부분에 기여하고 있다.
(1) LLM-AS-A-JUDGE 시스템 관련 연구
(2) MT-bench와 Chatbot Arena로부터 고품질 질문과 다양한 사용자와의 상호작용 정보를 내포하는 선호도 데이터셋 연구
2. MT-Bench and Chatbot Arena
2.1 Motivation
다양한 벤치마크들이 주로 폐쇄형(closed-ended) 질문과 간략한 응답을 사용한 모델의 평가에 초점을 두고 있다.
현재의 벤치마크는 대략 다음 3개의 분류로 나눌 수 있다.
- Core-knowledge benchmarks : zero-shot 또는 few-shot 벤치마크를 사용해 사전학습된 LLM의 주요(핵심) 능력을 평가하기 위한 벤치마크. (MMLU, HellaSwag, ARC, Wino-Grande, HumanEval, GSM-8K, AGIEval)
- Instruction-following benchmarks : Instruction fine-tuning 이후의 LLM을 평가하기 위해, 보다 개방적인(open-ended) 질문과 다양한 task로 확장된 벤치마크. (Flan, Self-instruct, NaturalInstructions, Super-NaturalInstructions)
- Conversational benchmarks : 의도된 유즈케이스와 가장 가까운 벤치마크이나, 질문의 다양성과 복잡성이 최근의 챗봇의 능력을 평가하기에는 어려움이 있다. (CoQA, MMDialog, OpenAssitant)
2.2 MT-Bench
80개의 고품질 멀티턴 질문으로 구성된 벤치마크로, 먼티턴 대화와 지시대처 능력 시험을 목적으로 설계되었다. 사용자 프롬프트에 따라 8가지 일반적인 분류로 식별한다 (작문, 역할극, 추출, 추론, 산술, 코딩, 지식1-STEM, 지식2-인류/사회과학). 각 분류는 수동적으로 설계된 10개의 멀티턴 질문으로 구성되었다.
2.3 Chatbot Arena
크라우드소싱의 벤치마크 플랫폼으로 동일 질문에 대해 두 개의 익명 모델과 상호작용하고, 선호하는 응답에 투표하는 방식으로 데이터를 생성/수집한다. 플랫폼에서는 기-정의된 질문을 사용하지 않기 때문에 사용자가 관심을 가지는 다방면의 샘플(use cases)을 수집할 수 있다.
3. LLM as a Judge
전통적인 평가 메트릭은 출력과 참조답변 사이의 유사도를 기반으로 하고있으며(ROUGE, BLEU), 이는 참조답변이 없는 개방형 질문들을 다루기에는 비효율적인 문제가 있다.
따라서 여기서는 최근 발전하고 있는 LLM이 chat의 응답을 효과적으로 평가하고, 사람의 선호도와 일치하는지를 확인하기 위한 수단으로 사용할 수 있을지에 대해 알아보고, LLM-as-a-judge의 사용과 한계점에 대해서 논의한다.
3.1 Types of LLM-as-a-Judge
우리는 LLM-as-a-judge로 3개의 변형에 대해 제안하며, 각각은 독립적으로 혹은 조합으로서 구현될 수 있다.
- Pairwise comparison : LLM judge는 하나의 질문과 두 개의 답변으로 표현되고, 어느 답변이 더 나은지 혹은 동일한 수준인지를 결정하는 유형
- Single answer grading : 양자택일로, LLM judge는 단일 답변에 대한 하나의 점수로 직접 채점하는 유형
- Reference-guided grading : 사용 가능한 참조 답변(해결책)을 제시하는 유형 (하나의 예로 수학 문제 채점을 위한 프롬프트가 될 수 있다. 원문 Figure 8 참조)
3.2 Advantages of LLM-as-a-Judge
LLM-as-a-judge는 확장성(scalability)과 설명능력(explainability) 측면의 두 가지 이점을 제공한다. 이는 사람의 개입을 줄이고 벤치마크의 확장과 빠른 반복수행을 가능하게하며, LLM judge로 평가 점수와 더불어 설명까지 함께 제공해 줄 수 있다.
3.3 Limitations of LLM-as-a-Judge
우리는 LLM judge의 편향(bias)과 한계점에 대해 확인했으나, 이후의 장에서 해결책에 대해 알아볼 것이며, 이러한 한계점에도 불구하고 사람의 평가와 일치율이 높다는 결과에 대해 살펴볼 것이다.
Position bias
위치 편향(position bias)이란 LLM이 특정한 위치에 대해 선호하는 경향을 나타내는 것을 말한다. 이러한 편향은 우리의 문맥(실험)에만 한정된 것이 아니라 사람의 의사결정이나 다른 ML 도메인에서도 볼 수 있는 현상이다.
GPT-4를 사용해 개방형 질문에 대한 GPT-3.5와 Vicuna-13B의 응답 결과를 평가하는 경우를 예시로 들자면, GPT-4는 GPT-3.5의 답변이 먼저 제시되는 경우 GPT-3.5의 답변이 더 상세하고 우수하다고 평가한 반면, GPT-3.5와 Vicuna-13B 응답의 위치를 바꾸어 Vicuna-13B 응답이 먼저 제시되는 경우에는 Vicuna-13B의 답변이 더 상세하고 우수하다고 평가했다. (즉, 어느 답변이 먼저 제시되느냐에 따라서 평가 결과가 달라졌다.)
위치 편향을 분석하기 위해, 우리는 MT-bench의 두 개의 first-turn 질문을 사용해 GPT-3.5에 두 번 반복시험하여 유사한 답변을 만들었다. 이후 세 개의 LLM에 두 개의 다른 프롬프트를 사용했다. 하나는 기본(default) 프롬프트이고, 다른 하나는 편향이 위치(position)로 부터 발생하는지 혹은 이름(name)으로부터 발생하는지를 확인하기 위한 목적으로 assistant 이름을 재설정한 "rename" 프롬프트이다. 시험한 결과 모든 LLM에서 강한 위치편향을 나타냈고, Claude-v1의 경우 이름편향도 확인할 수 있었다. (오직 GPT-4만이 샘플의 60% 이상에서 일관성 있는 결과를 출력했다.)
Verbosity bias
장황함(?) 편향은 LLM이, 명확하거나 고품질의 응답이 아니더라도, 길고 장황한 응답을 상대적으로 선호하는 현상을 말한다.
장황함 편향을 설명하고자, 우리는 MT-bench로부터 모델 응답에 대한 "반복 목록"(repetitive list)을 설계했다. 반복 목록은 우선 MT-bench로부터 23개의 모델 응답을 선별하고, GPT-4에 새로운 정보는 아니지만 불필요한 어휘를 만들어 추가하도록 요청한 뒤, 해당 목록을 기존 목록의 앞에 추가하는 방식으로 구성했다. 예를들어 기존 5개의 응답이 있었다면, 5개의 신규 응답을 목록의 제일 앞단에 붙여 총 10개의 응답으로 목록을 구성했다. 우리는 LLM이 이렇게 새롭게 구성된 응답이 이전 응답보다 더 좋은 답이라고 판단한 경우를 "공격에 성공했다"라고 정의했다. 공격에 대한 LLM 판단 실패율(=공격 성공률)은 Claude-v1의 경우 91.3%, GPT-3.5의 경우 91.3%로 대부분 장황함 편향이 발생했으며, GPT-4의 경우 8.7%로 다른 LLM에 비행 상당히 잘 방어했다.
Self-enhancement bias
우리는 LLM이 스스로 생성한 답변을 LLM 판단 과정에서 선호하는지 여부를 설명하고자, 사회 인지 문학으로부터 "자가-강화 편향" 조건에 대해 시험해보았다.
우리는 Figure 3과 같이 통계적으로 이러한 효과에 대해 설명하고자한다.
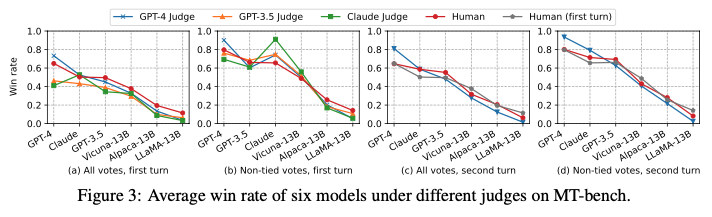
Figure 3의 (b)는 서로 다른 LLM과 사람의 판단에 대한 6개 모델의 승률을 나타낸다. 여기서 사람과 비교했을 때 어떤 판단이 특정 모델을 선호하는지에 대해 관측했다. 예를들어, GPT-4는 본인이 판단한 결과에 대해 10% 높은 승률을, Claude-v1의 경우는 25% 높은 승률을 보였다. 하지만 Claude-v1은 다른 모델에 대해서도 보다 높은 선호도를 보였고, GPT-3.5의 경우는 반대로 스스로에 대한 선호도가 낮았다. 이는 아마도 한정된 데이터와 작은 변화(difference)가 원인인 것으로 보이며, 모델이 자가-강화 편향을 나타내는지 여부를 확정하기는 어려웠다. 품질을 변형하지 않고 다른 모델에 적합한 스타일의 응답으로 변형하는 것이 쉽지 않기에, 완전히 제어된 연구를 수행하는 것은 어려울 것이다.
Limited capability in grading math and resoning questions
LLM은 산술과 추론 능력에 한계가 있다고 알려져 있으며, 질문에 대한 올바른 정답을 모르기 때문에, 채점 작업에 어려움이 있다. 그러나 더 흥미로운 사실은 기초 수학 문제를 풀이할 능력을 가지고 있음에도 채점 과정에서 이러한 한계점이 발생한다는 것이다. 한 가지 예로, GPT-4애 초등 수학문제를 풀도록 요청했을 때, 개별적/단계별로 문제를 풀 때는 잘 해결한 반면, 정답을 제공하는 과정에서는 잘못 된 유도과정으로 최종적으로는 오답인 결과를 도출했다. 이러한 결과는 추론 질문 예시에서도 찾을 수 있으며, GPT-3.5와 Claude-v1에서도 동일한 취약점을 보였다.
3.4 addressing limitations
우리는 수학 문제에 한해서 위치 편향과 제한된 채점 능력을 설명하고자 몇 가지 방법을 시도했다.
Swapping positions.
위치 편향은 간단한 해결방법(solution)으로 다루어 볼 수 있다. 보수적인 방법으로는 두 가지 답변의 순서를 바꾸었을 때도 답변이 동일하면 해당 답변을 사용하고, 답변이 달라지는 경우에는 동점으로 취급하는 "judge twice" 방법이 있다. 진취적으로는 답변 순서를 무작위로 할당하는 방법이 있으며, 이는 큰 규모의 예측에서 보다 효과적일 수 있다.
Few-shot judge
우리는 few-shot이 위치 편향 벤치마크에서 일관성을 향상시킬 수 있는지에 대해 몇 가지 샘플로 평가해보았다. 세 가지 평가 샘플을 사용했으며, 이는 MT-bench-like 질문 대상으로 GPT-3.5와 Vicuna를 사용해 답을 생성하고, GPT-4로 판단하는 방식으로 샘플을 생성했다. 샘플은 "A답이 더 나음", "B답이 더 나음", "동일함"의 세 가지 경우로 구분했다.
평가 결과 few-shot judge는 GPT-4의 일관성을 65%에서 77.5%로 상당히 높였으나, 높은 일관성이 반드시 높은 정확도를 나타낸다고 할 수는 없으며, 또 다른 편향을 일으키지는 않았는지에 대해서 확신하지 못했다.
Chain-of-thought and reference-guided judge
우리는 수학 채점과 추론 문제에 있어서 제한된 능력을 발휘하는 LLM의 문제점 완화 목적으로 간단한 2가지 방법을 제안한다. CoT (Chain-of-thought)는 LLM의 추론 능력을 향상시키기 위해 널리 사용되는 방법이다. 우리는 LLM judge 프롬프트에 이와 유사한 기술을 적용해 개별 질문에 답한 이후에 채점을 수행하도록 했다. 하지만 CoT 프롬프트를 사용하더라도 문제풀이 과정에서 이전과 완전히 동일한 문제가 발생했다.
이를 해결하고자 LLM judge 답변을 독립적으로 생성하고, 해당 답변을 참조 답변으로써 judge prompt에 노출하는 참조-안내 (reference-guided) 방법을 적용했다. 그 결과 기존 prompt 대비 실패율이 70% 에서 15%로 낮추는 상당한 성능 향상을 보였다.
Fine-tuning a judge model
우리는 Vicuna-13B 모델에 arena 데이터를 사용해 judge로서 행동할 수 있도록 fine-tuning을 수행했고, 기대할만한 결과를 얻었다. (상세정보는 논문의 Appendix F 참조)
3.5 Multi-turn judge
MT-bench에서 대화 능력을 평가하기 위한 모든 질문은 두 턴을 포함하고 있어, 두 보조자(assistant)를 비교하기 위해서는 두 개의 질문과 네 개의 응답 전체를 나타내야하므로 프롬프트 설계를 어렵게 만드는 문제가 있다. 우리는 가능한 설계로 (1) 두 개의 턴을 두 개의 프롬프트로 쪼개는 방법과 (2) 단일 프롬프트의 온전한 대화로 만들어 사용하는 방법을 실험해보았다. 전자의 경우는 LLM Judge (GPT-4)가 직전의 응답을 이해하는데 (정확한 위치를 찾는데) 어려움을 나타냈고, 결국 잘못된 판단을 내렸다. 이는 LLM judge가 더 나은 문맥 이해를 위해서는 온전한 대화를 나타내는 것이 필요하다는 것을 시사한다. 이후 대안으로, 후자에서 사용한 두 개의 대화를 하나의 프롬프트로 만들어 사용하는 방법을 사용하고, 두 번째 질문에 더 집중하도록 LLM judge에 요청해 보았다. 이 경우에는 전술한 참조 이슈를 그나마 완화시킨다는 것을 확인할 수 있었다.
4. Aggrement Evaluation
우리는 MT-bench와 Chatbot Arena 데이터셋에 대하여 LLM 판단과 사람 사이의 차이점에 대해 연구했다. 우리는 또한 MT-bench에서 사람간의 일치율에 대해서도 살펴보았다.
4.1 Setup
MT-bench : 6개 모델 (GPT-4, GPT-3.5, Claude-V1, Vicuna-13B, Alpaca-13B, LLaMA-13B) 대상 80개 모든 질문에 대한 답을 생성하고, LLM과 58명의 전문가 수준의 라벨러(labeler)에게 판단을 요청했다. LLM에는 모든 (질답) 쌍을 평가도록하고, 사람에게는 최소 20개의 무작위 멀티-턴 질문을 평가도록했다. 모든 질문에 대한 약 3천개의 투표 결과를 얻을 수 있었다.
Chatbot Arena : 우리는 3만개의 arena 데이터 중 3천개의 단일턴 투표 결과를 무작위로 샘플링했다. 이 과정에서 LLM의 판단과 IP 기반 웹 사용자의 판단, 두 가지 결과를 사용했다.
Metric : 우리는 두 유형의 일치율을, 무작위로 선별된 주체(LLM or Human가 무작위로 선택된 질문에 대해 서로 일치하는지를, 확률로서 정의했다.
* Metric 관련 참고사항 (Appendix D.3)
일치율 평가에 있어서는 사람간의 비교보다는 GPT와 사람과의 비교에 대한 일치율이 높을 수 있다. 예로 하나의 질문에 대해 세 사람이 각자 A, A, B로 평가했을 경우, 사람간의 비교에서는 (A, A), (A, B), (A, B)로 1/3 일치율을 나타낸다. 하지만 GPT와 사람간의 비교에서는 GPT가 A를 선택한 경우 2/3의 일치율을 나타내고, B를 선택한 경우 1/3 일치율을 나타낸다. 즉, 사람간의 비교는 무조건 1/3의 일치율이지만 GPT는 경우에 따라 2/3 일치율을 나타낼 수도 있다.
이런 정보를 나타내고자 우리는 다수의 사람이 선호하는 (human-majority) 결과를 기반으로 GPT와 사람의 평가 일치율을 계산했으며, 다수의 결과가 없는 경우(처음 평가되는 샘플 또는 선호도가 동일한 경우)는 1/2의 일치율로 계산했다.
* LLM과 사람의 평가간 일치율 (Appendix D.4)
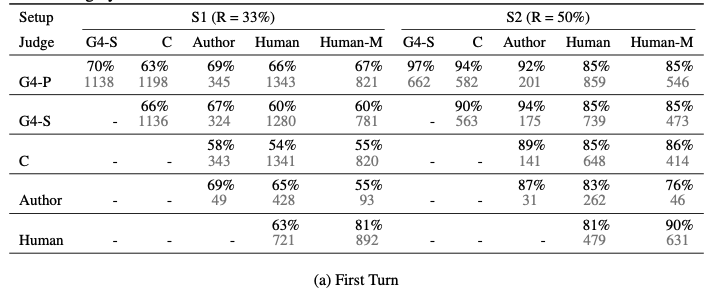
G4-P : GPT-4 pariwise comparison
G4-S : GPT-4 single-answer grading
C : Claude
Human-M : Majority vote of humans
S1 : 동점 및 (position bias로 인한) 비일관적인 결과 (동점처리) 모두 포함
S2 : 동점 제외한 결과
4.2 High agreement between GPT-4 and humans
우리는 MT-bench 데이터에 대한 일치율을 계산했고, GPT-4를 사용한 답변 비교(pairwise comparison)와 답변 채점 (answer grading)에서 전문가가 평가한 결과와 높은 일치율을 보인다는 것을 확인했다. GPT-4의 경우 동점을 제외한 비교에서 사람과 85%의 일치율을 보였으며, 이는 사람간의 일치율 결과인 81%보다도 높은 수치이다. 즉, GPT-4가 대다수의 사람이 평가한 결과에 가까운 판단을 한다는 것이다. 데이터를 수집 중, 사람이 GPT-4의 판단과 다르게 선택한 경우에 대해서 GPT-4의 판단을 사람들에게 보여주고 합리적인지 평가하도록 요청했다. 사람들은 GPT-4와 관점이 달랐음에도 불구하고, 75%의 사람들이 GPT-4의 판단이 합리적이라 수긍했으며, 그 중 34%는 자신의 판단을 번복할 수 있음에 응답했다.
Arena로부터 도출된 데이터도 비슷한 양상을 보였다. GPT-4 및 다른 LLM에 대한 사람과의 일치율을 비교했을 때 동점을 제외한 경우 사람과 일치율이 비슷했으며, GPT-4의 일치 개수가 가장 높았다. 이는 GPT-4에서 위치 편향이 가장 적게 발생함을 의미한다. (시험에서 위치 편향이 발생하는 경우에는 동점으로 처리함)
MT-bench와 Arena 데이터 모두에서, GPT-4는 단일-답변 채점 결과가 GPT-4의 비교와 사람의 선호도와 매우 잘 일치했다. 이는 GPT-4가 가끔 답변 비교에서 일치율이 약간 떨어지고, 동점인 결과가 더 발생하더라도, 상대적으로 안정적인 내부 규정을 따라 확장성을 가진다는 것을 뜻한다.
이후 동점을 제외한 데이터만를 사용해 서로 다른 모델과 분류의 일치율을 계산하는 방법으로 분해 분석법(breakdown analysis)을 수행했다. 우리는 비교 모델(model pairs)간의 성능 차이에 따라서 GPT-4와 사람의 일치율이 75%에서 거의 100%까지 증가하는 것을 관측했으며, 이는 모델간의 성능 차이가 큰 경우 GPT-4가 사람과 더 잘 일치함을 의미한다.
4.3 Win rates under different judges
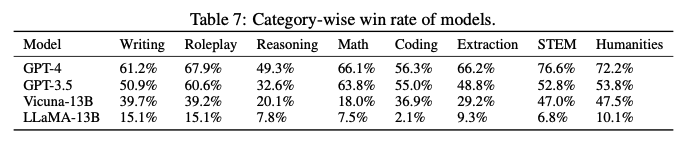
MT-bench와 Chatbot Arena 각각에 대해 유형별 모델의 평균 승률을 표로 정리했다. LLM judges의 승률은 사람과 거의 일치했으며, GPT-4의 성능이 가장 우수했다.
5. Human Preference Benchmark and Standardized Benchmark
생략
6. Discussion
생략
7. Conclusion
생략
'AI' 카테고리의 다른 글
| [LLM] llama 3 주요 정보 정리 (0) | 2024.04.24 |
|---|---|
| [Torch] pyTorch 자주 쓰는 명령어 정리 (0) | 2024.04.23 |
| [Paper] G-EVAL : NLG Evaluation using GPT-4 with Better Human Alignment (2) | 2024.03.13 |
| [Paper] Evaluating Large Language Models: A Comprehensive Survey (0) | 2024.03.05 |
| [Article] LLM Judge (0) | 2024.01.03 |

