
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- Package
- Flask
- 책갈피
- numpy
- PostgreSQL
- Python
- git
- Paper
- Linux
- pytorch
- TORCH
- LLM
- Laravel
- Container
- list
- file
- Database
- Windows
- DB
- KAKAO
- GitLab
- evaluation
- Mac
- judge
- docker
- enV
- pandas
- Converting
- format
- AI
- Today
- Total
Daily Develope
[Paper] 2023 gemini technical report (LLM/MMLU 관련내용) 정리 본문
"Gemini: A Family of Highly Capable Multimodal Models" 기술 레포트 내용에서 MMLU 관련내용 및 평가방법(5.1절)까지 내용 중 필요한 부분만 발췌&정리
1. Introduction
Gemini 1.0은 모델 크기에 따라 Ultra, Pro, Nano로 나눌 수 있다. Gemini Ultra의 경우는 MMLU 영역에서 인간 전문가를 뛰어 넘은 최초의 모델이다.
사용 가능성
- 교육 : 지저분하게 작성된 문제 및 풀이과정을 이해하고, 깔끔한 수식으로 표현해 줄 수 있으며, 잘 못된 풀이부분을 되짚어줄 수 있다.
- 프로그래밍 : AlphaCode2에 활용해, 프로그래밍 플랫폼인 Codeforce에서 입문자 상위 15%, 상급자 상위 50%의 성능을 보여주었다.
2. Model Architecture
Gemini 모델은 Transformer decoder 아키텍처를 사용하고, Google의 TPU(Tensor Processing Units) 기반으로 훈련과 추론이 가능하도록 최적화해서 만들었다.
32k 문장을 받을 수 있도록 훈련되었다.

Gemini 모델은 textual 입력과 넓고 다양한 부분의 청각, 시각 자료 등 (이미지, 도표, 스크린샷, PDF, 비디오) 상호 배치하여 입력되는 경우도 처리할 수 있도록 훈련되었다. 출력 또한 이미지와 텍스트의 조합으로 가능하다.
음성 부분에서는 USM 특성으로부터 16kHz 신호를 직접 수집하는 방법을 사용해 음성을 텍스트로 맵핑하는 과정에 손실될 수 있는 음영(nuances)을 잘 잡아내 처리할 수 있다.
3. Training Infrastructure
(생략)
4. Training Dataset
Gemini 모델은 multimodal과 multilingual 모두를 담고 있는 하나의 데이터셋으로 학습되었다.
SentencePiece Tokenizer 사용하고, 전체 corpus 에 대해 tokenizer를 학습하여 추론된 vocabulary와 모델 성능을 향상시켰다.
다수의 토큰은 (Hoffmann이나 기타 접근법을 따라 결정된) 가장 큰 모델을 학습하기 위해 사용되었다. 가장 작은 모델은 (Touvron 등에 의해 선호된 접근법과 유사하게) 주어진 추론 자원 한도 내에서의 성능을 향상시키기 위한 목적으로 더 많은 토큰을 사용해 학습되었다.
모든 데이터셋에 대해 heuristic 정책과 model기반 분류기법을 사용했고, 유해한 내용을 제거하기 위해 safety 필터링을 수행했다. 평가셋은 훈련 corpus로부터 필터링해 사용했다.
5. Evaluation
추론, 독해, STEM, 코딩 영역에 대한 평가를 포함한, 텍스트 기반 학술 밴치마크 수행.
CoT(Chain-of-Thought Prompting) 접근법의 조합을 적용.
5.1.1. Academic Benchmarks

수학
- GSM8K (초등학교 수학 밴치마크 데이터셋) : 94.4% (CoT-SC 사용)
- 중/고등학교 수학 능력 검사 밴치마크 데이터셋 : 53.2% (4-shot prompting 사용)
- American 수학 능력 검사 (2022 & 2023년도 150개 문제) : 32% 문제 풀이
코딩
- AlphaCode 2 (Gemini를 기반으로 하고있는 프로그래밍 AI) 대상 성능 및 추론 시험
- HumanEval (함수 기술에 대한 기술을 Python 구현으로 맵핑해주는 code-completion 밴치마크 표준)에 대해 74.4% 문제에 대한 정답을 구현
- Natural2Code (웹에 노출되지 않은 데이터셋)에 대해서는 74.9%의 점수 기록
평가 주의사항
평가는 사전학습되는 데이터의 조합에 따라서 쉽게 달라질 수 있으므로 주의해야한다.
Gemini 평가를 위해 사용되는 LAMBADA나 HellaSwag 데이터의 경우 외부 노출 및 오염의 문제가 발생할 수 있어, 최근 나온 평가 데이터셋인 WMT23, Math-AMC 2022-2023 문제, 그리고 내부의 Natural2Code 를 활용해 평가를 진행했다.
5.1.2. Trends in Capabilities
50개 이상의 벤치마크 전체 데이터로부터 6가지 능력에 따라 Gemini-Pro 기준으로 모델의 우수성 평가를 진행했다. 이로부터 모델 크기 증가에 따른 성능 개선의 정도를 확인 할 수 있다.
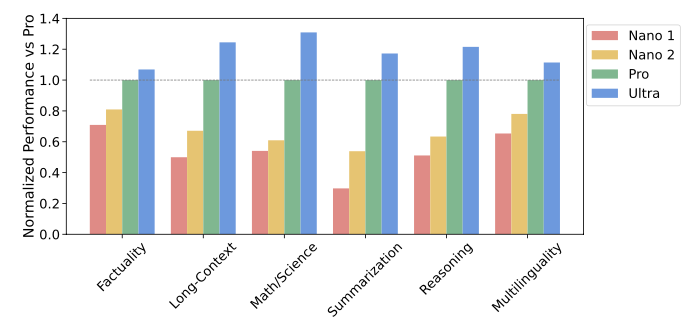
능력별 평가기준
- Factuality (사실성) : open/closed-book을 다루는 검색과 QA task
- Long-Context (장문) : 장문에 대한 요약, 검색, QA task
- Math/Science : 수학적인 문제 해결, 정리 증명, 과학적 예시
- Summarization : 요약
- Reasoning (추론) : 산술, 과학, 상식 추론
- Multilingual : 다중 언어에 대한 번역, 요약, 추론
5.1.4. Multilinguality (다중언어 능력)
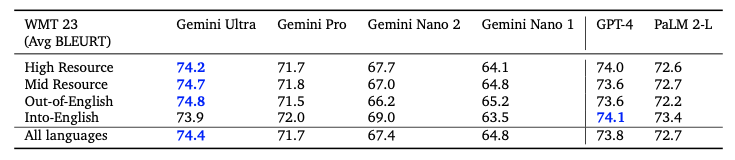
Gemini 모델은 다중언어 능력이 필요로하는 이해력(multilingual understanding), 언어간 교차생성(cross-lingual generalization), 다중 언어의 텍스트 생성의 다양한 task set에 대한 평가를 진행했다. 해당 task에서는 기계 번역 벤치마크(WMT 23 for high-medium-low resouce translation), 요약 벤치마크(XLSum, Wikilingua), 번역 벤치마크(MGSM:11개 언어로의 전문적인 번역)를 포함한다.
Machine Translation
WMT 23 번역 벤치마크에 대해, few-shot 설정과 함께 전체 언어 쌍에 대한 instruction-tuning을 적용하고, 평균 BLEURT 점수를 사용해 Gemini Ultra를 평가했다. 영어에서 다른 언어로의 번역에는 주목할만한 성능을 보였고, 영어 이외의 번역에서는 LLM 기반 번역 중 가장 우수한 성능을 보였다.
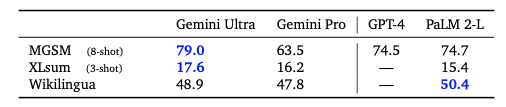
Multilingual Math and Summarization
번역 외에도 수학과 다중언어 요약 관련한 평가 수행
- 수학의 경우 GSM8K 벤치마크의 변수를 번역한 MGSM 벤치마크 대상으로 평가
- 요약의 경우 SLSum과 WikiLingua 벤치마크에 대해 rougeL 점수를 사용해 평가
5.1.5. Long Context
Gemini 모델은 32,768 토큰의 sequence 길이로 학습되었고, 이는 장문을 효과적으로 사용할 수 있도록 만든다는 것을 알 수 있었다.
이를 검증하기 위해 우선 종합적인 검색(synthetic retrieval)에 대한 시험을 수행했다 (key-value 쌍을 문장의 시작부에 두고 장문을 추가한 뒤 특정 key와 관련된 value에 대해 묻는 방식). 그 결과 Ultra 모델은 최대 문장 길이에 대해 질의 했을 때 98%의 정확도로 올바른 value 값을 검색해냈다.
나아가, 긴 문서에 대한 token index별 NLL(negative log likelihood)을 조사한 결과 최대 문장 길이인 32K 까지 NLL이 지속적으로 감소하는 것을 확인했다. (즉, 문장이 길어짐에 따람 손실률이 적어지는 것을 뜻하며, 이는 문장이 길어질 수록 검색의 정확도가 높아지는 것으로 해석할 수 있다.)
5.1.6. Human Preference Evaluations
모델 출력에 대한 사람의 선호도는 자동화된 평가를 보충하기 위한 중요한 품질의 지표이다. 여기서는 Gemini Pro와 PaLM 2를 대상으로, 동일한 prompt에 대한 blind 테스트를 수행했다. 비교는 창의성(창의적 글쓰기), 지시 이행 (multimodal 이해, 장문 이해), 안정성 등 의 항목에 대해 이루어졌다.

5.1.7. Complex Reasoning Systems
AlphaCode 2는 방대한 프로그램 공간에서 목적에 맞는 코드를 검색하고, 프로그래밍 문제를 푸는데 도움을 주기 위한 목적으로 Gemini Pro의 특수한 버전을 사용한다. 이 과정에서 Gemini Pro는 제안 솔루션 후보를 제시하기 위한 코딩 모델이 될 수 있고, 또한 적합한 코드 후보를 인식하고 사용할 수 있도록 하는 보상 모델(reward model)이 될 수도 있다.
Codeforce의 division1과 2의 총 77문제 프로그래밍 문제에 대해서 기존 AlphaCode는 25%, AlphaCode 2는 43%, Gemini Pro 위에 구축된 AlphaCode 2는 85%를 풀었다. 이는 기존 대비 50%의 성능 향상이라는 의미있는 진보라 할 수 있다.
Reference & Keyword
- MMLU : Multi-task Language Understanding
- MMMU : Massive Multi-discipline Multimodal Understanding
- CoT : Chain-of-Thought Prompting
- CoT 및 프롬프트 기술 정리
'AI' 카테고리의 다른 글
| [Paper] Evaluating Large Language Models: A Comprehensive Survey (0) | 2024.03.05 |
|---|---|
| [Article] LLM Judge (0) | 2024.01.03 |
| [AI] Optimizer 옵티마이저 참조 (0) | 2023.10.18 |
| [AI] Hugginface, sklearn, torch 샘플 코드 및 설명 (0) | 2023.10.17 |
| [AI] CUDA & PyTorch Windows 설치 / 환경설정 (with WSL2) (0) | 2023.08.01 |

